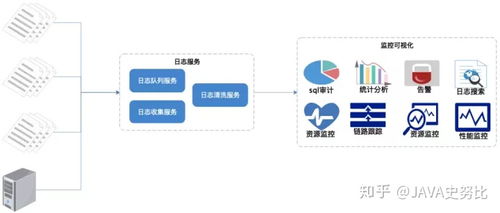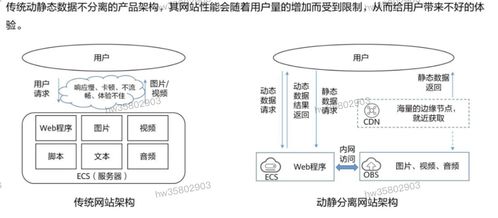
在HCIP存储服务规划的学习中,数据处理与存储服务是确保数据价值有效释放和业务连续性的核心环节。本章节将重点探讨数据处理流程设计、存储服务选型策略以及典型场景下的架构实践。
一、数据处理流程规划
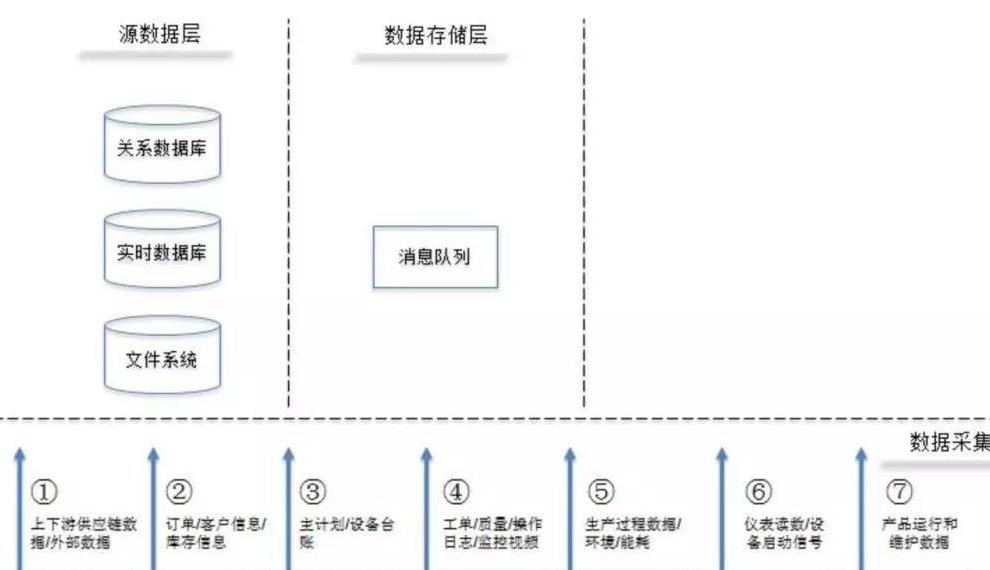
数据处理通常遵循“采集-传输-处理-存储-应用”的闭环逻辑。在规划时需明确:
- 数据采集层:确定数据来源(业务数据库、日志、IoT设备等),设计实时/批量采集策略,并考虑格式统一与初步过滤。
- 数据传输层:根据延迟和带宽要求,选择消息队列(如Kafka)、数据同步工具或直连传输,保障数据流动的可靠性与安全性。
- 数据处理层:部署流处理(如Flink)或批处理(如Spark)引擎,实现数据清洗、转换、聚合等操作,为存储与分析做准备。
- 质量控制:建立数据校验、去重与异常监测机制,确保进入存储的数据合规可用。
二、存储服务选型策略
存储服务需匹配数据处理目标与业务特征:
- 在线事务处理(OLTP)场景:选用关系型数据库(如MySQL、PostgreSQL),注重ACID特性与高并发读写能力。
- 在线分析处理(OLAP)场景:面向海量数据分析,可选数据仓库(如ClickHouse、Hive)或OLAP数据库,优化复杂查询性能。
- 非结构化数据场景:对象存储(如AWS S3、华为云OBS)适用于图片、视频等大文件;文档数据库(如MongoDB)适合半结构化JSON数据。
- 缓存与加速场景:引入Redis或Memcached作为热数据缓存层,减轻后端存储压力,提升响应速度。
三、典型架构实践
- 混合云数据湖架构:
- 将原始数据统一存入对象存储构建数据湖,保留原始格式。
- 通过数据处理服务转换后,将结构化的结果存入数据仓库供BI工具分析。
- 优势在于兼顾灵活性与成本,支持多源数据长期留存与按需计算。
- 实时数据处理流水线:
- 采集端数据实时写入消息队列,流处理引擎进行实时计算。
- 计算结果同步写入时序数据库(如InfluxDB)用于监控仪表盘,同时备份至对象存储供后续回溯。
- 适用于IoT监控、实时风控等低延迟场景。
- 存储分层设计:
- 根据数据热度实施分层策略:热数据存于高性能SSD,温数据存于标准云硬盘,冷数据归档至廉价对象存储或磁带库。
- 结合生命周期管理策略自动迁移数据,优化总体拥有成本(TCO)。
四、关键考量点
- 一致性权衡:根据业务容忍度选择强一致性(如金融交易)或最终一致性(如社交动态)。
- 扩展性设计:采用分库分表、读写分离或分布式存储(如Ceph)支撑业务增长。
- 灾备与高可用:通过跨可用区部署、数据多副本及定期备份保障数据持久性。
- 安全合规:实施数据加密(传输/静态)、访问控制及审计日志,满足行业监管要求。
数据处理与存储服务规划需以业务需求为锚点,通过合理的技术选型与架构设计,构建高效、可靠且经济的数据管线。实际落地中应持续评估性能指标与成本效益,并随业务演进迭代优化。