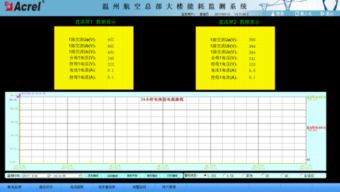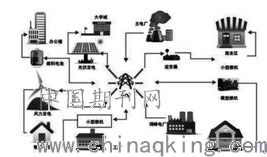
随着智能电网的快速发展,电网调控运行过程中产生了海量的数据,包括实时监控数据、设备状态信息、负荷预测数据、故障记录等。这些数据不仅规模巨大,而且具有高速、多样性和复杂性等特点,传统的存储和处理技术已难以满足需求。因此,电网调控运行大数据的存储及处理技术成为提升电网智能化水平的关键支撑。数据处理和存储服务在这一过程中扮演着核心角色,确保了数据的可靠性、实时性和可扩展性。
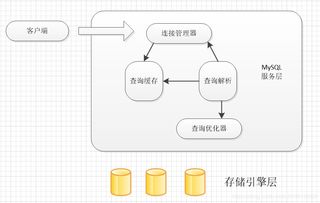
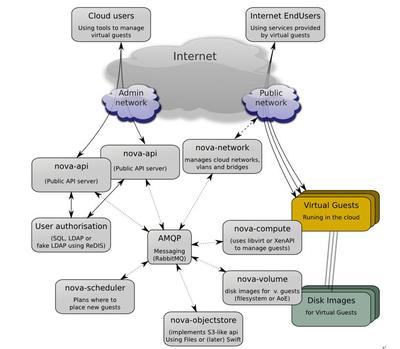
大数据存储技术是电网调控运行的基础。电网数据通常包括结构化数据(如电压、电流等参数)和非结构化数据(如图像、视频和日志文件)。为了高效存储这些数据,现代电网系统采用分布式存储架构,如Hadoop HDFS或云存储方案。这种架构能够实现数据冗余备份和水平扩展,确保在设备故障时数据不丢失,同时支持存储PB级别的数据。时间序列数据库(如InfluxDB)被广泛应用于存储实时监控数据,因为它优化了时序数据的读写性能,便于快速查询历史记录和趋势分析。通过这种存储技术,电网调控系统能够长期保存关键数据,为后续分析提供坚实基础。
数据处理技术是实现电网智能调控的核心。电网数据流通常具有高吞吐量和低延迟的特点,需要实时处理以支持快速决策。流处理框架如Apache Kafka和Apache Flink被广泛应用于实时数据流处理,它们能够对电网监控数据进行即时分析,例如检测异常事件或预测负荷波动。同时,批处理技术(如Spark)用于离线分析大规模历史数据,帮助电网运营商进行长期趋势预测和设备维护规划。数据处理服务还包括数据清洗、融合和聚合步骤,以消除噪声并整合来自不同源的数据,确保数据质量。通过机器学习和人工智能算法,数据处理服务还能实现故障诊断、优化调度和能源分配,提升电网的稳定性和效率。
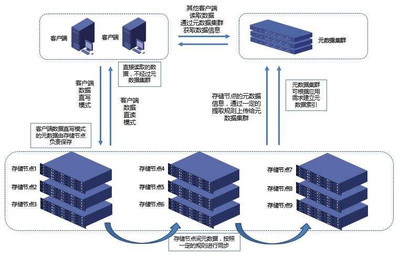
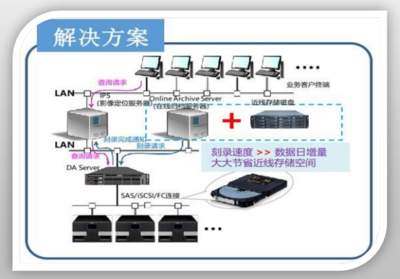
数据处理和存储服务在电网调控中的集成应用至关重要。一个典型的服务架构包括数据采集层、存储层、处理层和应用层。在数据采集层,传感器和智能设备收集原始数据,并通过网络传输到存储系统。存储层负责数据的持久化和索引,支持快速检索。处理层则通过实时和批处理引擎分析数据,并将结果反馈给应用层,如监控界面或决策支持系统。这种分层服务模式确保了数据的端到端管理,提高了系统的响应速度和可靠性。例如,在电网故障事件中,数据处理服务可以实时识别故障点,存储服务则保存相关日志,便于事后分析和改进。
电网调控运行大数据也面临挑战,如数据安全、隐私保护和系统可扩展性。数据处理和存储服务必须采用加密技术和访问控制机制,防止未授权访问和数据泄露。同时,随着电网规模的扩大,服务需要支持弹性扩展,以应对不断增长的数据量。未来,随着5G和边缘计算技术的发展,数据处理和存储服务将更加分散化,实现更快速的本地处理和云端协同。
电网调控运行大数据存储及处理技术是推动电网智能化转型的关键。通过高效的数据处理和存储服务,电网系统能够实现实时监控、智能分析和优化运行,最终提升能源利用效率和供电可靠性。随着技术的不断演进,这些服务将继续创新,为构建可持续的智能电网贡献力量。