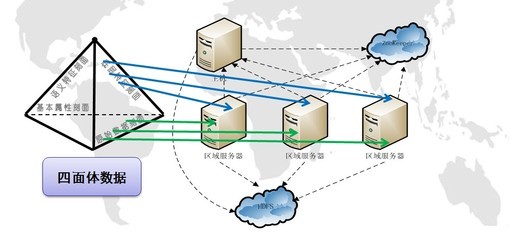
随着大数据和云计算技术的飞速发展,传统的数据存储和处理方式已难以满足现代企业日益增长的需求。分布式数据存储与并行处理技术应运而生,成为构建高效、可扩展数据处理和存储服务的核心解决方案。
一、分布式数据存储的基本原理与优势
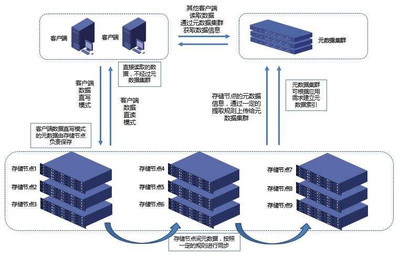
分布式数据存储通过将数据分散存储在多个节点上,实现数据的冗余备份和负载均衡。其核心原理包括:
- 数据分片:将大数据集分割成多个小块,分布到不同的存储节点。
- 冗余机制:通过副本或纠删码技术,确保数据的高可用性和容错能力。
- 一致性协议:如Paxos或Raft,保障分布式系统中数据的一致性。
优势体现在:
- 高可扩展性:可轻松添加节点以应对数据增长。
- 高可靠性:单点故障不会导致数据丢失。
- 成本效益:利用普通硬件构建大规模存储系统。
二、并行处理技术的关键组件
并行处理旨在通过多个处理单元同时执行任务,显著提升数据处理效率。关键组件包括:
- 任务并行化:将大型任务分解为子任务,分配给不同处理器。
- 数据并行化:对数据集进行分区,每个处理器处理一部分数据。
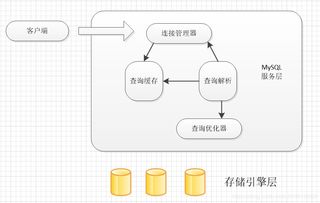
- 分布式计算框架:如Apache Hadoop和Apache Spark,提供底层支持。
并行处理的优势:
- 高性能:大幅缩短数据处理时间,尤其适合实时分析。
- 资源优化:充分利用计算资源,避免瓶颈。
- 灵活性:支持批量处理和流式处理等多种模式。
三、分布式数据存储与并行处理的结合应用
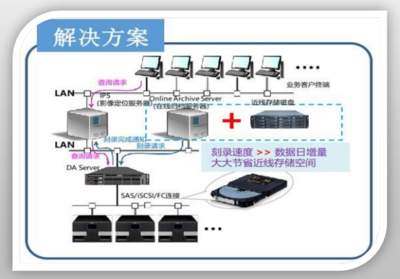
将分布式存储与并行处理结合,可构建强大的数据处理和存储服务。典型应用场景包括:
- 大数据分析:企业利用HDFS存储数据,并通过Spark进行并行计算,实现快速洞察。
- 实时流处理:如Kafka与Flink结合,处理高吞吐量数据流。
- 云存储服务:AWS S3和Google Cloud Storage提供分布式存储,配合EMR或Dataproc实现并行处理。
四、面临的挑战与未来趋势
尽管分布式数据存储与并行处理技术已成熟,但仍面临挑战:
- 数据一致性与延迟的平衡:在分布式环境中确保强一致性可能增加延迟。
- 安全与隐私:多节点存储增加了数据泄露风险。
- 运维复杂度:需要专业知识和工具进行管理。
未来趋势包括:
- AI驱动的优化:利用机器学习自动调整存储和计算资源。
- 边缘计算集成:将分布式技术延伸到边缘设备,支持物联网应用。
- Serverless架构:进一步简化部署和管理,提升用户体验。
分布式数据存储与并行处理是构建现代数据处理和存储服务的基石。通过合理设计和实施,企业能够实现高效、可靠的数据管理,驱动业务创新和增长。