随着大数据时代的到来,海量数据的存储、处理和分析成为企业和开发者面临的核心挑战。对象存储(Object Storage Service, OSS)以其高可扩展性、高可靠性和低成本的优势,已成为数据湖架构的基石。在此之上,构建一个集成的智能数据分析处理框架,能够极大地提升数据价值挖掘的效率和深度。
一、 核心框架:对象存储OSS作为统一数据湖
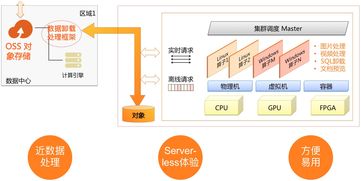
该框架的核心是将OSS定位为企业的统一数据湖。所有原始数据、中间处理结果和最终分析数据都存储在OSS中,形成一个单一、可扩展的真相源。其优势在于:
- 无限扩展:存储容量可随数据增长无缝扩展,无需预先规划。
- 成本低廉:采用按需付费模式,冷热分层存储进一步优化成本。
- 高持久性:提供高达99.9999999999%(12个9)的数据持久性,保障数据安全。
- 开放兼容:支持标准API(如S3协议),便于各类数据处理工具直接访问。
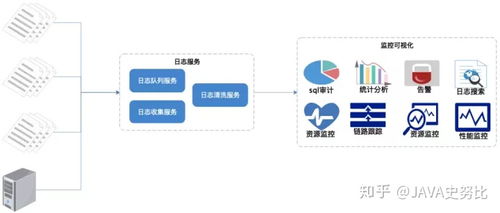
二、 智能数据处理功能与服务
基于OSS的数据湖,框架提供分层、自动化的数据处理流水线,涵盖从数据摄入到智能洞察的全过程。
1. 数据接入与预处理服务
- 多源异构数据接入:支持从数据库、日志文件、IoT设备、应用程序等实时或批量将数据写入OSS。利用OSS的SDK、命令行工具或可视化客户端轻松完成。
- 自动化数据预处理:集成无服务器计算服务(如AWS Lambda、阿里云函数计算FC),通过事件触发器(如OSS文件上传事件)自动触发数据清洗、格式转换(如JSON、Parquet、ORC)、压缩和分区操作,为后续分析做好准备。
2. 弹性计算与数据处理引擎
- 查询加速与元数据管理:结合数据目录服务(如AWS Glue Data Catalog、阿里云DataWorks),自动爬取OSS中的数据并建立元数据,支持表结构定义。通过索引和缓存技术加速查询。
- 无服务器化数据处理:利用云原生的大数据服务(如AWS EMR Serverless、阿里云EMR on ACK)或交互式查询服务(如AWS Athena、阿里云DataLake Analytics),直接对OSS中的数据进行SQL查询、批处理(Spark、Flink)和流处理,无需管理底层集群,实现真正的弹性伸缩。
3. 高级分析与AI集成
- 机器学习与模型训练:将OSS作为特征库和训练数据源,直接与机器学习平台(如AWS SageMaker、阿里云PAI)集成。支持从数据准备、模型训练、评估到部署的全流程,生成的模型可再次存入OSS。
- 智能内容处理:利用与OSS无缝集成的AI服务(如阿里云智能媒体管理IMM、AWS Rekognition),自动对存储的图片、视频、文档进行内容分析(如标签识别、人脸分析、文本抽取),并将结构化结果写回OSS,丰富数据维度。
4. 统一的数据治理与安全
- 生命周期管理:基于策略自动将数据在不同存储层级(标准、低频、归档)间移动,优化性能和成本。
- 细粒度权限控制:通过Bucket Policy、RAM策略或STS临时授权,精确控制何人、何应用在何种条件下访问哪些数据。
- 审计与监控:记录所有数据访问和操作日志,并集成监控告警服务,保障数据处理的合规性与可观测性。
三、 典型应用场景与价值
- 日志分析与运营监控:将应用、服务器日志实时存入OSS,通过无服务器查询服务快速分析错误趋势、用户行为。
- 物联网(IoT)数据分析:海量设备数据写入OSS,利用流处理框架进行实时风控、预测性维护。
- 推荐系统与用户画像:将用户行为数据沉淀至OSS数据湖,结合机器学习服务训练和更新推荐模型。
- 多媒体内容智能管理:自动对海量图片/视频进行AI打标、分类,构建可搜索的多媒体资产库。
###
基于对象存储(OSS)的智能数据分析处理框架,成功地将低成本、高可靠的数据存储与弹性、智能的数据处理能力相结合。它打破了数据孤岛,提供了一条从原始数据到商业洞察的敏捷、高效的路径。通过充分利用云原生的无服务器计算和AI服务,企业能够以更低的运维成本和更快的创新速度,应对日益复杂的数据挑战,真正实现数据驱动的智能决策。